1. Introduction
In the digital landscape, where content is not just king but the entire kingdom, protecting your valuable content is paramount. Content scraping, a practice where automated bots or scripts extract information from websites without permission, poses a significant threat to WordPress websites. WordPress, being one of the most popular content management systems globally, is a prime target for content scrapers due to its widespread use and the accessibility of its content.
Content scraping can lead to various issues, including duplicate content, loss of traffic, and potential copyright infringement. As a website owner, it’s crucial to understand the impact of content scraping and the strategies available to combat it.
This article delves into the world of content scraping in WordPress, exploring the reasons behind it, its impact on websites, and the methods to detect and combat it effectively. By the end of this article, you will have a comprehensive understanding of content scraping and the tools and strategies at your disposal to protect your valuable content.
2. What is Content Scraping in WordPress?
Content scraping, also known as web scraping or data scraping, is the process of extracting information from websites using automated bots or scripts. These bots are programmed to crawl websites, access their content, and copy it for various purposes, such as republishing on other websites, aggregating for news or research, or creating automated content.

The practice of content scraping is not new, but with the proliferation of online content and the ease of access provided by content management systems like WordPress, it has become more prevalent. Content scrapers typically target websites with valuable or high-quality content, as it can be repurposed for their own gain without the effort of creating original content.
Content scraping can include copying text, images, videos, and other media from websites. Scrapers often use sophisticated techniques to avoid detection, such as rotating IP addresses or using proxies to mask their identity. This makes it challenging for website owners to detect and prevent content scraping effectively.
The impact of content scraping can be significant for website owners, as it can lead to duplicate content issues, loss of traffic, and potential copyright infringement. Website owners must be vigilant in monitoring their content and taking steps to protect it from scrapers.
Now, we will explore why people engage in content scraping, how it impacts websites, and the strategies you can use to detect and combat it effectively.
3. Why Do People Scrape Content?

Content scraping is a widespread practice on the internet, with individuals and organizations scraping content for various reasons. Understanding these motivations can provide insights into why content scraping occurs and how it can impact websites.
- Automated Content Generation: One of the primary reasons people scrape content is to generate automated articles or blog posts. By scraping content from various sources, individuals can create new content without the need for manual writing. This is particularly common in industries where content needs to be updated frequently, such as news or product reviews.
- SEO Benefits: Content scraping can also be used to improve a website’s search engine optimization (SEO). By republishing high-quality content from other websites, scrapers can attract traffic and improve their website’s ranking in search engine results pages (SERPs). This is often done by targeting keywords and topics that are popular or trending.
- Monetary Gain: Scraped content can be monetized in various ways, such as through advertising or affiliate marketing. By attracting traffic to their website using scraped content, individuals can generate revenue from ads or affiliate links placed on their site.
- Content Aggregation: Some scrapers engage in content scraping to aggregate content from multiple sources and create a comprehensive resource on a particular topic. This can be useful for users looking for information on a specific subject, as it provides them with a centralized source of information.
- Competitive Analysis: Content scraping can also be used for competitive analysis, where individuals scrape content from competitor websites to gain insights into their strategies, content topics, and audience engagement. This information can be used to improve their own website and content strategy.
While these motivations may seem beneficial to the individuals engaging in content scraping, it’s important to recognize that scraping content without permission is a violation of copyright law and can have negative consequences for website owners. Now, we will explore the impact of content scraping on websites and the strategies you can use to detect and combat it effectively.
4. How Does Content Scraping Impact Websites?

Content scraping can have a range of negative impacts on websites, affecting their search engine rankings, traffic, and overall reputation. Here are some key ways in which content scraping can impact websites:
- Duplicate Content Issues: When scraped content is republished on other websites without any modification, it can lead to duplicate content issues. Search engines like Google prioritize unique and original content, so having duplicate content can negatively impact a website’s SEO and rankings. Websites that scrape content may outrank the original source in search results, causing the original website to lose traffic and visibility.
- Loss of Traffic and Revenue: If a scraper’s website ranks higher than the original source in search engine results pages (SERPs), the original website may experience a significant loss of traffic. This can result in a decline in revenue, especially for websites that rely on advertising or affiliate marketing for income. Additionally, if users find the scraped content on another website before finding the original source, they may be less likely to visit the original website.
- Copyright Infringement: Content scraping without permission is a violation of copyright law. Website owners have the exclusive right to reproduce, distribute, and display their content, and scraping content without permission infringes on these rights. Website owners can take legal action against scrapers for copyright infringement, which can lead to legal expenses and damage to the scraper’s reputation.
- Impact on User Experience: When users encounter scraped content on a website, it can impact their overall experience. They may perceive the website as less trustworthy or credible if they find that the content has been stolen from elsewhere. This can lead to a decline in user engagement and loyalty.
- Resource Consumption: Content scraping can also consume server resources, especially if scrapers are accessing the website frequently to extract content. This can lead to slower website performance and increased hosting costs for the website owner.
In summary, content scraping can have a range of negative impacts on websites, including duplicate content issues, loss of traffic and revenue, copyright infringement, negative impact on user experience, and increased server resource consumption. Website owners must take steps to protect their content from scrapers and mitigate these impacts effectively.
5. Detecting Content Scraping

Detecting content scraping can be challenging, as scrapers often use sophisticated techniques to avoid detection. However, there are several signs that website owners can look out for to determine if their content has been scraped:
- Spike in Referral Traffic: A sudden increase in referral traffic from unknown sources can be a sign that your content has been scraped and republished on another website. Monitoring your website’s traffic sources regularly can help you identify unusual patterns that may indicate scraping activity.
- Duplicate Content in Search Results: Performing a search for exact phrases from your content can help you identify if the content has been republished elsewhere. If you find that your content is ranking lower in search engine results pages (SERPs) than a scraped version, it may indicate that your content has been scraped.
- Unusual Activity in Server Logs: Monitoring your server logs for unusual activity, such as multiple requests for the same content within a short period, can help you detect scraping attempts. Scrapers often use automated bots that make frequent requests to extract content, which can be identified in server logs.
- Monitoring Content Aggregators: Content aggregators or scraper websites may republish your content without permission. Monitoring these websites regularly can help you identify if your content has been scraped and take appropriate action.
- Using Google Alerts: Setting up Google Alerts for key phrases or topics from your content can help you monitor if your content is being republished elsewhere. Google Alerts will notify you when new content matching your specified criteria is indexed by Google.
- Analyzing Backlinks: Scraper websites may link back to your website as the original source of the content. Analyzing your website’s backlink profile can help you identify if your content has been scraped and republished on other websites.
Detecting content scraping requires vigilance and proactive monitoring of your website’s traffic, search engine rankings, server logs, and mentions of your content on other websites. By staying alert to these signs, you can take action to protect your content and mitigate the impact of scraping on your website.
6. Strategies to Fight Back Against Content Scraping

Fighting back against content scraping requires a multi-faceted approach that combines technological solutions with legal action. Here are some effective strategies you can use to protect your content from scrapers:
6.1. Copyright Notices and Watermarks
Adding copyright notices and watermarks to your content can be an effective deterrent against content scraping. Copyright notices serve as a clear indication that the content is protected by copyright law and should not be reproduced without permission. Watermarks, on the other hand, are visible overlays on images or videos that contain information about the copyright owner, such as a logo or text.
How Copyright Notices Work:

A copyright notice typically includes the symbol ©, the year of publication, and the name of the copyright owner. For example, “© 2024 Your Website Name.” Placing this notice at the bottom of your website’s pages or within the content itself informs visitors that the content is protected by copyright and should not be copied or reproduced without permission.
How Watermarks Work:

Watermarks are visible overlays that are applied to images or videos to indicate ownership. They can be simple text overlays with the copyright owner’s name or logo, or they can be more complex graphics that are difficult to remove. Watermarks make it clear that the content is copyrighted and can deter scrapers from stealing it. One of the free Watermark Plugin is Easy Watermark by BracketSpace.
Benefits of Copyright Notices and Watermarks:
- Deterrence: Copyright notices and watermarks act as a deterrent against content scraping by making it clear that the content is protected by copyright law.
- Identification: If your content is scraped and republished elsewhere, the presence of a copyright notice or watermark can help identify it as your original content.
- Legal Protection: Copyright notices and watermarks provide legal protection for your content, making it easier to take legal action against scrapers who violate your copyright.
Best Practices for Using Copyright Notices and Watermarks:
- Placement: Place copyright notices at the bottom of your website’s pages or within the content itself where they are clearly visible. Watermarks should be applied to images or videos in a way that does not detract from the content but is still visible enough to deter theft.
- Consistency: Use consistent copyright notices and watermarks across all your content to establish a strong brand presence and make it easier to identify your content.
- Clear Terms of Use: In addition to copyright notices and watermarks, include clear terms of use on your website that specify how your content can be used and under what circumstances.
- Regular Monitoring: Regularly monitor the internet for unauthorized use of your content and take action against violators.
By implementing copyright notices and watermarks, you can protect your content from unauthorized use and deter content scrapers from stealing your valuable intellectual property.
6.2. Using RSS Feed Limits
Limiting the number of items in your website’s RSS feed is a proactive measure to prevent content scraping. RSS (Really Simple Syndication) feeds are commonly used to distribute content updates to users and other websites. By setting limits on your RSS feed, you can control how much content scrapers can access and republish from your website.
How RSS Feed Limits Work:
RSS feeds typically include the titles and summaries of your website’s latest articles or posts. By limiting the number of items in your RSS feed, you can restrict the amount of content that scrapers can access and republish. For example, you can set your RSS feed to only include the titles and summaries of the latest 5 articles, preventing scrapers from accessing older content.
You can change the settings by going to Settings » Reading in your WordPress admin panel. You need to select the ‘Excerpt’ option and then click the ‘Save Changes’ button.
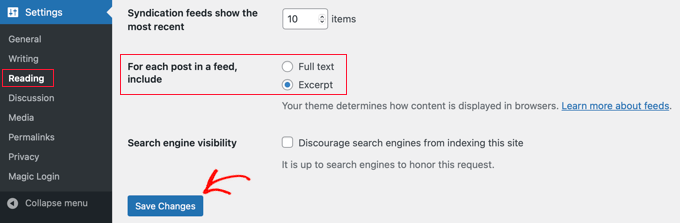
Benefits of Using RSS Feed Limits:
- Control Over Content: By setting limits on your RSS feed, you can control how much content scrapers can access and republish, reducing the risk of your entire content being scraped.
- Deterrence: Limiting your RSS feed can deter scrapers from targeting your website, as they may find it less attractive if they can only access a limited amount of content.
- Protection Against Scraping: RSS feed limits provide an additional layer of protection against content scraping, making it more difficult for scrapers to access and republish your content in bulk.
Best Practices for Using RSS Feed Limits:
- Set Reasonable Limits: While it’s important to limit your RSS feed to prevent scraping, make sure the limits are reasonable and don’t negatively impact your legitimate users. For example, setting a limit of 5-10 items in your RSS feed is a reasonable approach.
- Update Frequency: Consider reducing the frequency of updates in your RSS feed to further limit the amount of content available to scrapers. For example, you can set your RSS feed to update once a day instead of every time a new article is published.
- Monitor Usage: Regularly monitor your RSS feed usage to detect any unusual activity that may indicate scraping attempts. Look for spikes in access patterns or unusual IP addresses accessing your feed.
- Use Feed Management Tools: Consider using feed management tools or plugins that offer advanced features for controlling and protecting your RSS feed, such as limiting access based on IP address or user agent.
By implementing RSS feed limits, you can protect your content from being scraped and republished without permission. Combined with other strategies, such as copyright notices and watermarks, RSS feed limits can help safeguard your content and maintain its value and integrity.
6.3. Implementing Anti-Scraping Plugins
One of the most effective ways to protect your content from scraping is by using anti-scraping plugins. These plugins are specifically designed to detect and block scraping attempts, helping to safeguard your content and intellectual property. Here’s how you can implement anti-scraping plugins on your WordPress website:
How Anti-Scraping Plugins Work:
Anti-scraping plugins work by monitoring the activity on your website and identifying patterns that indicate scraping activity. They can detect when a scraper is attempting to access your content and block their IP address or user agent to prevent further access. Some plugins also offer features such as CAPTCHA challenges or rate limiting to further deter scrapers.
Benefits of Implementing Anti-Scraping Plugins:
- Automated Protection: Anti-scraping plugins provide automated protection against content scraping, reducing the need for manual intervention.
- Real-time Detection: These plugins can detect scraping attempts in real time, allowing you to take immediate action to block scrapers and protect your content.
- Customizable Settings: Many anti-scraping plugins offer customizable settings that allow you to adjust the level of protection based on your website’s specific needs. You can set rules to block access from certain IP addresses or user agents, or implement CAPTCHA challenges for suspicious activity.
Best Practices for Implementing Anti-Scraping Plugins:
- Choose a Reputable Plugin: Select an anti-scraping plugin from a reputable developer with a track record of providing effective protection against scraping.
- Regular Updates: Keep your anti-scraping plugin up to date to ensure it has the latest security patches and features to protect against new scraping techniques.
- Monitor Effectiveness: Regularly monitor the effectiveness of your anti-scraping plugin to ensure it is successfully blocking scraping attempts and protecting your content.
- Combine with Other Strategies: While anti-scraping plugins are effective, they work best when combined with other strategies such as copyright notices, watermarks, and RSS feed limits for comprehensive protection against scraping.
Implementing anti-scraping plugins on your WordPress website can significantly reduce the risk of your content being scraped and republished without permission. By using these plugins in conjunction with other protective measures, you can effectively safeguard your content and maintain control over its distribution and use.
6.4. Blocking IP Addresses
Blocking IP addresses associated with scraping activity is another effective strategy to protect your content from scrapers. By identifying and blocking IP addresses that are engaged in scraping your website, you can prevent scrapers from accessing your content and republishing it elsewhere. Here’s how you can implement IP address blocking on your WordPress website:
How IP Address Blocking Works:
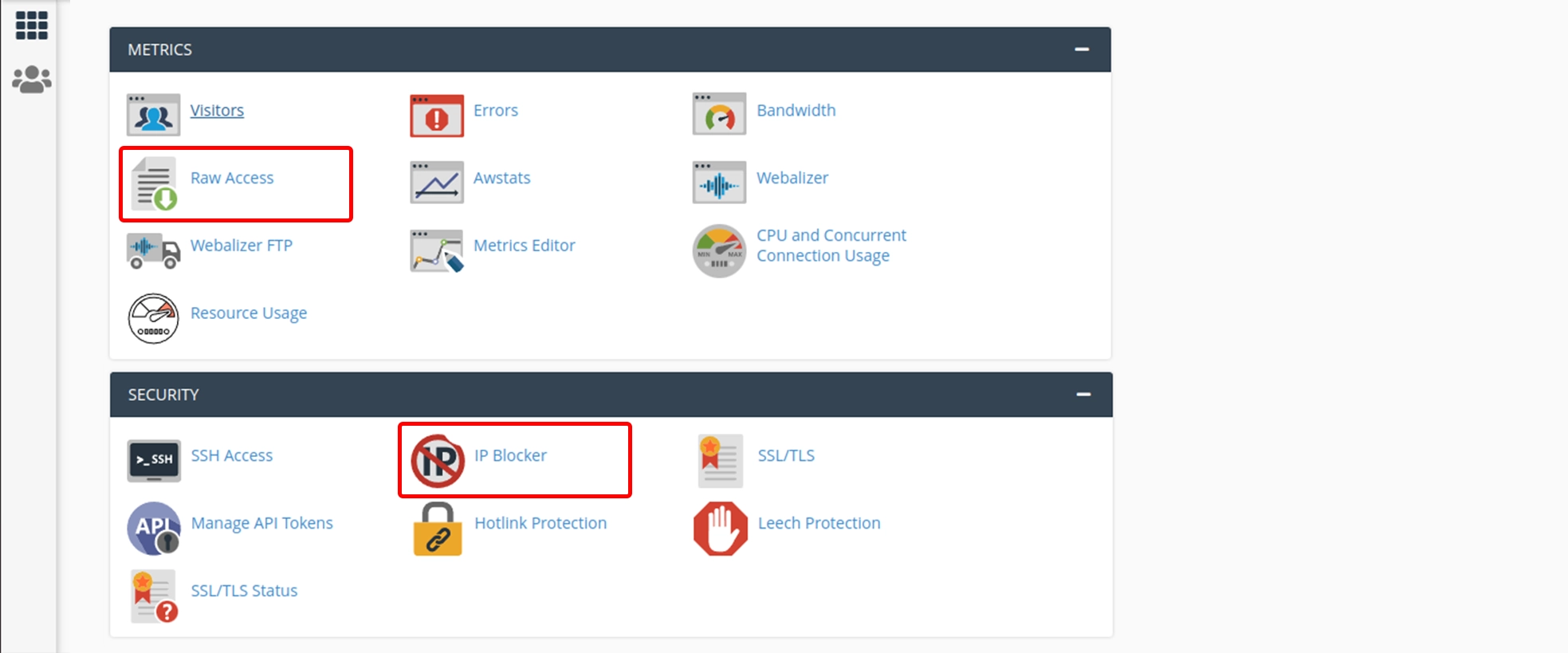
IP address blocking involves identifying the IP addresses of scrapers and configuring your website’s server or firewall to block access from those IP addresses. When a scraper attempts to access your website, their IP address is checked against a list of blocked IP addresses, and if there is a match, access is denied.
Benefits of Blocking IP Addresses:
- Immediate Protection: Blocking IP addresses provides immediate protection against scraping, as access from known scrapers is denied automatically.
- Customizable Blocking Rules: You can customize the blocking rules to block access from specific IP addresses, ranges of IP addresses, or based on other criteria such as user agent or request frequency.
- Deterrence: Knowing that their IP address may be blocked can deter scrapers from targeting your website, as they will be aware of the consequences of their actions.
Best Practices for Blocking IP Addresses:
- Regular Monitoring: Regularly monitor your website’s access logs to identify IP addresses that may be engaged in scraping activity. Look for patterns such as frequent requests for the same content or unusual access patterns.
- Automated Blocking: Consider using automated tools or scripts to block IP addresses associated with scraping activity automatically. This can save time and ensure that scrapers are blocked promptly.
- Review Blocked IP Addresses: Periodically review the list of blocked IP addresses to ensure that legitimate users are not inadvertently blocked. Remove any IP addresses that are no longer associated with scraping activity.
- Combine with Other Strategies: IP address blocking works best when combined with other strategies such as anti-scraping plugins and copyright notices for comprehensive protection against scraping.
By blocking IP addresses associated with scraping activity, you can effectively protect your content from being scraped and republished without permission. This proactive approach can help maintain the integrity and value of your content and ensure that it is used in accordance with your terms and conditions.
6.5. Legal Action
If you discover that your content has been scraped, you may consider taking legal action against the scraper for copyright infringement. Copyright infringement occurs when someone copies, distributes, or displays your copyrighted work without permission. Here’s how you can take legal action against content scrapers:
How to Take Legal Action:
- Cease-and-Desist Letter: The first step in taking legal action against a content scraper is to send them a cease-and-desist letter. This letter informs the scraper that their actions are infringing on your copyright and demands that they stop using your content immediately. In many cases, a cease-and-desist letter is enough to resolve the issue without further legal action.
- Digital Millennium Copyright Act (DMCA) Takedown Notice: If the scraper does not comply with your cease-and-desist letter, you can file a DMCA takedown notice with the hosting provider of the website where the scraped content is published. The DMCA provides a legal framework for copyright holders to request the removal of infringing content from websites.
- Legal Complaint: If the scraper continues to use your content despite your efforts to stop them, you may consider filing a legal complaint against them. This typically involves hiring a lawyer to draft and file a complaint in court, seeking damages for copyright infringement.
Benefits of Taking Legal Action:
- Protecting Your Rights: Taking legal action against content scrapers sends a clear message that you will not tolerate infringement of your copyright and helps protect your rights as a content creator.
- Deterrence: Legal action can act as a deterrent against future scraping attempts, as scrapers may be deterred by the potential legal consequences of their actions.
- Recovery of Damages: If you are successful in your legal action, you may be entitled to recover damages for the infringement, including lost revenue or licensing fees.
Best Practices for Taking Legal Action:
- Document Evidence: Keep detailed records of the scraping activity, including screenshots, access logs, and any communication with the scraper. This evidence can be crucial in proving your case.
- Consult with Legal Counsel: Before taking legal action, it’s advisable to consult with a lawyer who specializes in copyright law. They can provide guidance on the best course of action and help you navigate the legal process.
- Be Prepared for a Legal Battle: Legal action can be time-consuming and expensive, so be prepared for a potentially lengthy legal battle if the scraper decides to contest the charges.
Taking legal action against content scrapers is a serious step that should be taken after careful consideration. However, it can be an effective way to protect your content and assert your rights as a copyright holder.
Strategies to Ignore Content Scraping

While fighting back against content scraping can be effective, some website owners may choose to ignore scrapers and focus on other strategies to protect their content. Here are some strategies you can use to ignore content scraping:
7.1. Focusing on Quality Content
One of the most effective ways to combat content scraping is by focusing on creating high-quality, original content that is valuable to your audience. By consistently producing valuable content, you can make it less attractive for scrapers to steal your content. Here’s how you can focus on quality content:
- Unique and Engaging Content: Create content that is unique, engaging, and provides value to your audience. Focus on topics that are relevant and interesting to your target audience.
- Regular Updates: Regularly update your website with fresh content to keep your audience engaged and coming back for more. This can also help improve your website’s search engine rankings.
- Interactive Elements: Incorporate interactive elements such as quizzes, polls, or surveys into your content to increase engagement and make it more difficult for scrapers to replicate.
- Optimized for SEO: Use SEO best practices to optimize your content for search engines. This can help improve your website’s visibility in search results and make it more difficult for scrapers to outrank you.
- Build a Strong Brand: Focus on building a strong brand identity and loyal following. This can help differentiate your content from scraped content and make it more difficult for scrapers to replicate your brand.
By focusing on creating high-quality, original content, you can make your website less attractive to scrapers and improve your overall online presence.
7.2. Monitoring and Analyzing Scraped Content

Another strategy to consider is monitoring and analyzing scraped content to understand how your content is being used and identify potential opportunities. While this approach does not directly combat content scraping, it can provide valuable insights that can inform your content strategy and help you better protect your content in the future. Here’s how you can monitor and analyze scraped content:
- Use Online Tools: There are several online tools available that can help you monitor the internet for scraped versions of your content. These tools can alert you when new instances of scraped content are found, allowing you to take action if necessary.
- Analyze Scraped Content: When you discover scraped content, take the time to analyze it to understand how your content is being used. Pay attention to how the scraped content is being presented, whether it is being attributed to you, and if there are any modifications or additions.
- Identify Patterns: Look for patterns in how your content is being scraped. Are certain types of content or topics being targeted more frequently? Are there specific websites or individuals who are consistently scraping your content? Identifying these patterns can help you take targeted action to protect your content.
- Take Action if Necessary: If you discover that your content is being scraped and used inappropriately, consider taking action. This could involve sending a cease-and-desist letter to the scraper, filing a DMCA takedown notice, or pursuing legal action if the infringement is severe.
- Learn from Scraped Content: Use the insights gained from analyzing scraped content to improve your content strategy. For example, if you notice that certain types of content are being scraped more frequently, consider creating more of that type of content to capitalize on its popularity.
By monitoring and analyzing scraped content, you can gain valuable insights into how your content is being used and identify opportunities to protect your content more effectively in the future.
7.3. Leveraging Syndication and Licensing Opportunities

Instead of viewing content scraping as a threat, consider leveraging it as an opportunity to expand your reach through syndication and licensing agreements. By proactively syndicating your content to reputable websites or offering licensing agreements to interested parties, you can control how your content is used and potentially generate additional revenue. Here’s how you can leverage syndication and licensing opportunities:
- Identify Potential Partners: Research and identify reputable websites or organizations in your industry that may be interested in syndicating your content or entering into licensing agreements. Look for websites with a similar target audience and content focus.
- Reach Out to Potential Partners: Once you’ve identified potential partners, reach out to them to gauge their interest in syndicating your content or entering into a licensing agreement. Highlight the value of your content and how it can benefit their audience.
- Negotiate Terms: If a potential partner is interested, negotiate the terms of the syndication or licensing agreement. This may include the duration of the agreement, the territories in which the content will be syndicated, and any fees or revenue-sharing arrangements.
- Monitor Usage: Once your content is syndicated or licensed, monitor its usage to ensure that it is being used appropriately and in accordance with the terms of the agreement. This may involve periodically checking the partner’s website or using online tools to monitor for unauthorized use.
- Renegotiate or Terminate Agreements: Periodically review your syndication and licensing agreements to ensure that they are still beneficial. If necessary, renegotiate the terms of the agreement or terminate it if it is no longer serving your goals.
By leveraging syndication and licensing opportunities, you can control how your content is used and potentially generate additional revenue. This proactive approach can turn content scraping from a threat into an opportunity to expand your reach and enhance your brand’s visibility.
7.4. Emphasizing User Engagement and Community Building
Another effective strategy to combat content scraping is to focus on building a strong community around your content and engaging with your audience. By creating a loyal following of engaged users, you can make it more difficult for scrapers to replicate the value that your community provides. Here’s how you can emphasize user engagement and community building:
- Create High-Quality, Engaging Content: Focus on creating content that is valuable, informative, and engaging to your target audience. This will not only attract more visitors to your website but also encourage them to engage with your content and become part of your community.
- Encourage User Interaction: Encourage user interaction by enabling comments on your blog posts, integrating newsletter subscriptions, hosting forums or discussion boards, and actively engaging with your audience on social media. This can help foster a sense of community among your users and make them more loyal to your brand.
- Offer Exclusive Content: Reward your most loyal users with exclusive content or special offers that are only available to members of your community. This can help strengthen their loyalty and make them less likely to seek out content from scrapers.
- Provide Value Beyond Content: In addition to providing valuable content, offer other resources and services that can benefit your community, such as webinars, workshops, or online courses. This can help differentiate your website from scrapers and make it more valuable to your audience.
- Monitor and Respond to Feedback: Regularly monitor feedback from your community and respond promptly to any questions, concerns, or suggestions. This shows that you value their input and are committed to providing them with a positive experience.
By emphasizing user engagement and community building, you can create a loyal following of users who are less likely to seek out content from scrapers. This can help protect your content and brand reputation and make your website a more valuable resource for your audience.
Conclusion
In conclusion, content scraping is a serious concern for website owners and content creators, but it’s not insurmountable. By proactively addressing this issue, you can protect your valuable content and intellectual property. Implementing measures such as copyright notices, anti-scraping plugins, and legal action when necessary can help deter scrapers and assert your ownership rights.
Additionally, building a strong community around your content, educating your audience about copyright laws, and exploring syndication and licensing opportunities can further enhance your content’s protection. These strategies not only help protect your content but also contribute to a positive user experience and a stronger online presence.
It’s important to stay vigilant and regularly monitor your website for scraping activity. By staying informed about the latest developments in content scraping and adapting your strategies accordingly, you can effectively protect your content and maintain control over its use.
If you enjoyed this article, then you’ll love Zalvis's WordPress Hosting platform. Turbocharge your website and get 24/7 support from our veteran team. Our world-class hosting infrastructure focuses on auto-scaling, performance, and security. Let us show you the Zalvis difference! Check out our plans.


